2024年11月29日
星期五
近日,中国科学院合肥物质院安光所计算机视觉团队在全景场景图生成研究方面取得新进展,提出了一种基于CLIP知识转移和关系上下文挖掘的全景场景图生成方法,相关研究成果已被信号处理领域的顶级国际会议IEEE International Conference on Acoustics, Speech and Signal Processing (IEEE声学、语音与信号处理国际会议,ICASSP 2024)接收发表。
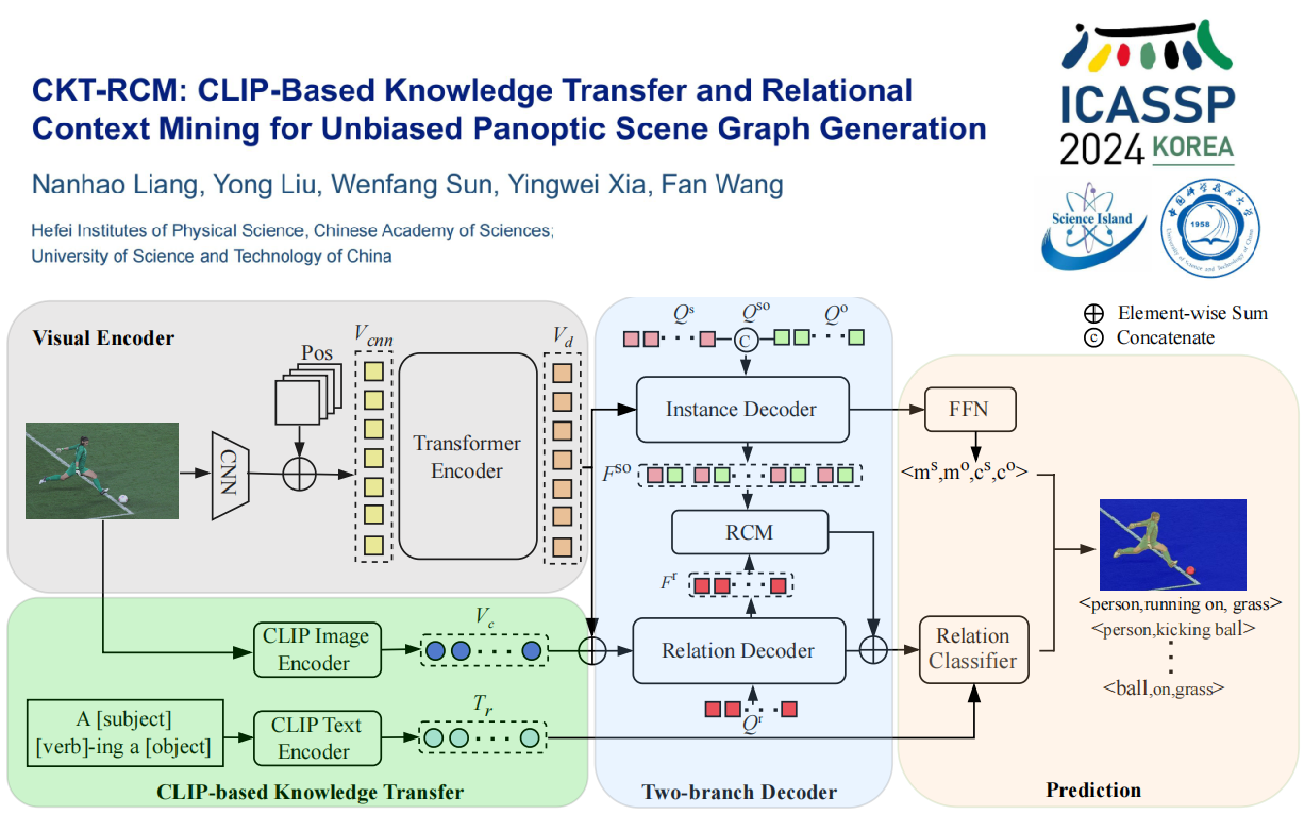
全景场景图生成(Panoptic Scene Graph,简称PSG)是当前场景图生成(Scene Graph Generation,简称SGG)领域中的热门研究方向之一,旨在基于图像的像素级分割信息,利用所有物体及它们之间的成对关系,进行全景场景图生成表示。然而,由于训练数据常呈现长尾分布,当前PSG方法的预测更倾向于高频和无信息的关系表示(例如“在”、“旁边”等),导致PSG与实际应用相距甚远。
针对上述问题,研究人员受人类先验知识的启发,引入了两个新颖的设计:一是使用预训练的视觉语言模型来校正数据倾斜性;二是使用条件先验分布对上下文关系进行进一步的预测质量提升。具体而言,研究人员首先从图像编码器中提取与关系相关的视觉特征,并通过从视觉语言模型的文本编码器中提取所有关系的文本嵌入,从而构建关系分类器。之后,利用主客体对之间的丰富关系上下文信息,通过交叉注意力机制促进上下文的关系精准预测。最后,研究人员在OpenPSG数据集上进行了全面的实验,并取得了最先进的性能。
博士研究生梁楠昊为论文第一作者,王凡博士后和刘勇研究员为论文通讯作者。该研究工作得到国家重点研发计划、国家自然科学基金、安徽省博士后研究人员科研活动经费资助项目、合肥物质院院长基金等项目支持。
文章链接:https://doi.org/10.1109/ICASSP48485.2024.10446810
新闻链接:https://www.hf.cas.cn/kxyj/kyjz/202404/t20240425_7131686.html
地址:安徽省合肥市蜀山湖路350号中科院安徽光机所一号楼
EMAIL:ahos@vplshi.com
